Bender and Koller (2020) provide a working definition of “understanding” as the ability to recover the communicative intent from an utterance. To achieve this, one must be able to query a set of concepts that is aligned with the speaker’s own understanding. An example of such alignment is interaction with the physical world, an experience shared by all humans. These experiences provide a common set of concepts to rely on in communication. For example, the reader can map the phrase “I dropped my pint glass” to a set of relevant experiences, generate a mental depiction of the scene, and reason about potential outcomes: the pint glass will fall toward the ground and will likely break on impact. Current language models lack this experience, which we hypothesize limits their ability to understand. To this end, the goal of our research is to demonstrate this limitation and then provide models with the necessary experiences to overcome it.
Published Work:
PROST: Physical Reasoning of Objects through Space and Time
A probing dataset highlighting why the lack of real-world experience hinders language understanding.
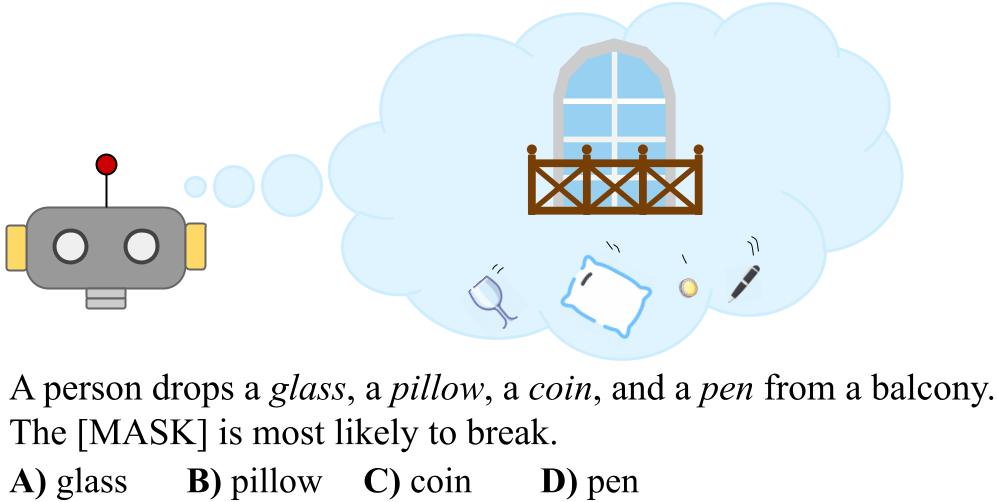
An example question from PROST.
Children grab, push, and play with the objects around them to form concepts about the world they live in even before learning to talk. These concepts are linked with words to enable communication, eventually providing the necessary grounds for concepts and language to co-develop. In contrast, current language models (LMs) are not exposed to real-world experiences, making them incapable of grounding language. We hypothesize that this lack of experience impedes their ability to both understand an utterance relating to the physical world, and their ability to reason about its implications. For this reason, we develop PROST: Physical Reasoning about Objects Through Space and Time, a dataset created to probe a language models physical reasoning. It contains 18,736 multiple-choice questions made from 14 manually curated templates, covering 10 physical reasoning concepts. All questions are designed to probe both causal and masked LMs in a zero-shot setting.
We conduct an extensive analysis of modern language models on PROST, which demonstrates that state-of-the-art pretrained models are weak at physical reasoning: they are influenced by the order in which answer options are presented to them; they struggle when the superlative in a question is inverted (e.g. most ↔ least); and increasing the amount of pretraining data and parameters only yields minimal improvements. These results provide support for the hypothesis that current pretrained models’ ability to reason about physical interactions is inherently limited by a lack of real world experience. By highlighting these limitations, we hope to motivate the development of models with a human-like understanding of the physical world.
For more information see our paper and our github
Future Work
We are continuing to look into both elucidating the limitations of text-only training as well as creating systems to overcome them.
Finding the limitations of text-only training
Grice’s conversational maxim of quantity asserts that utterances contain the minimum amount of information required. This makes explicit reporting of self-evident knowledge rare, while less common information is being reported at disproportionately high frequencies. This reporting bias inevitably propagates from corpora to the models trained on them and affects a variety of concepts. Color is one such concept that is easy to measure, and is solvable with a visual modality. To this end, we are investigating this relationship between reporting bias and modern LMs’ perception of color. Our results to date indicate that the distribution of colors a language model recovers correlates more strongly with the inaccurate distribution found in text than with the human generated ground-truth. This supports the claim that reporting bias negatively impacts and inherently limits text-only training. Building off of our hypothesis that experiences in other modalities may be able to mitigate this limitation, we also probe a multi-modal model and find, in support of our hypothesis, that it is better at mitigating the effects of reporting bias.
Overcoming the limitations of text-only training
Humans learn language through interactions that provide feedback and information about the world around us. Further, these interactive experiences are multi-modal, and it has been shown that multi-modal experiences can ground concepts that are more transferable than concepts generated from text alone. To this end, we see robots as the ideal vehicle to ground language; their range of sensors provide data across multiple modalities and their embodied actions enable them to interact with the world around them and generate salient experiences. This leads us to our first research direction: Can we leverage a robot’s experience to endow models with a more human-like understanding of the world?
This framework is also directly relevant to the area of natural language task specification in the robotics community. While many interesting directions have demonstrated success on narrow tasks, few make use of the generalizability and impressive progress of modern pre-trained LMs. This leads to us to our second research question: Can we use language to train robots that are more generalizable?
Please email Stéphane at stephane.aroca-ouellette@colorado.edu if anything on this page piques your interest (include [Q] in the subject line) or if you’re keen on collaborating (include [C] in the subject line). There is a lot of infrastructure engineering work that goes into these projects so help from most levels of technical capability is welcome, however a strong understanding of python is required. The following skills are particularly useful: knowledge of modern NLP systems, knowlege of robotic manipulation and control, knowledge of deep learning/reinforcement learning/self-supervised learning, pytorch.