When performing collaborative tasks with new unknown teammates, humans are particularly adept at adapting to their collaborator and converging toward an aligned strategy. However, state of the art autonomous agents still do not have this capability. We propose that a critical reason for this disconnect is that there is an inherent hierarchical structure to human behavior that current agents lack. We hypothesize that providing an autonomous agent with a hierarchical structure will cognitively and behaviorally align the agent to humans, facilitating human-agent teams to understand each other and adapt to aligned strategies. In this are of research, we explore how to use hierarchical structures to enable agents to navigate the complexities of ad hoc teaming at the same level of abstraction as humans.
HAHA: Hierarchical Ad Hoc Agents
The proliferation of autonomous agents in our everyday lives requires us to consider how we want these agents to interact with us. Increasingly, the AI community has recognized the importance of creating agents that can collaborate effectively with humans. Drastic variance in human knowledge, ability, and preference require adaptive agents that can quickly conform to new and unseen teammates—an ability frequently named ad hoc teaming [2] or zero-shot coordination [4]. Current state of the art methods for developing autonomous agents in multiplayer scenarios, such as self-play, were originally developed for competitive tasks. However, when applied to cooperative tasks, these methods tend to create agents that behave in rigid patterns and lack the ability to efficiently adapt to new teammates.
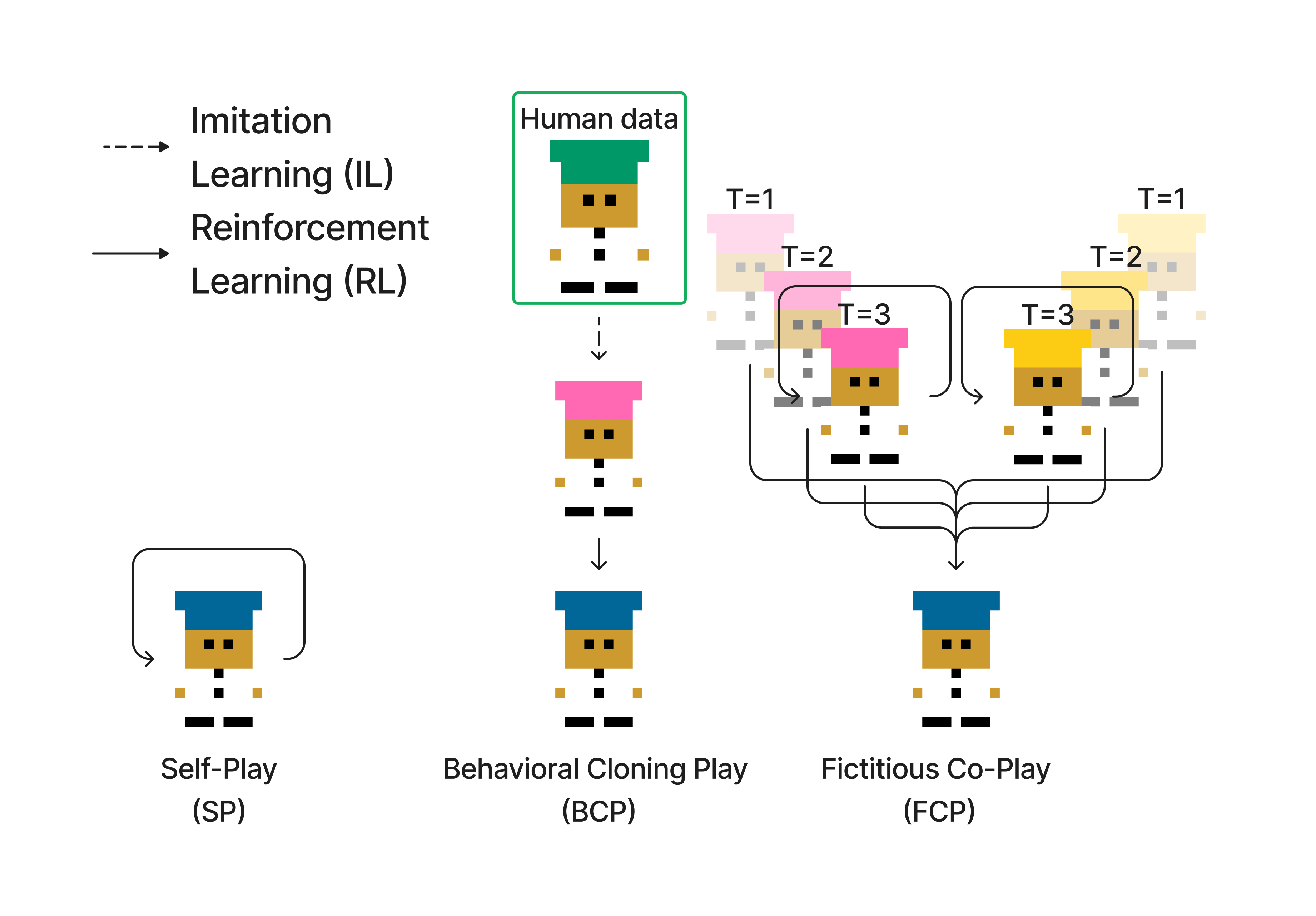
Previous work [3, 5] has focused on using different training partners to induce ad hoc teaming. In contrast, we focus on using hierarchical structures to align human and agent at a cognitive and behavioral level. Importantly, our method is fully compatible with all previous work.
Previous work has made valuable strides toward zero-shot coordination by having the training agent play with a teammate who resembles human behavior [3], or play with a diverse set of different teammates that vary in their skill level [5, 10]. However, the majority of this work has focused on low-level agents that output low level actions (e.g move left, right, up, down). Notably, there is an inherent hierarchical structure to human behavior [12] that these techniques fail to capture. Humans utilize task hierarchies to both analyze and manage projects [1,13] and synchronize with other humans [6,8,9]. In this work, we hypothesize that providing an autonomous agent with a similar hierarchical structure—with high level tasks (e.g. get an onion, serve the soup, …) that organize low-level actions—will facilitate human-agent teams to better understand each other and adapt to aligned strategies. To this end, we explore the use of hierarchical reinforcement learning (HRL) to train an agent that can navigate the complexities of ad hoc teaming at the same level of abstraction as humans. Specifically, we leverage FuNs [11] to develop HAHA: Hierarchical Ad Hoc Agents.
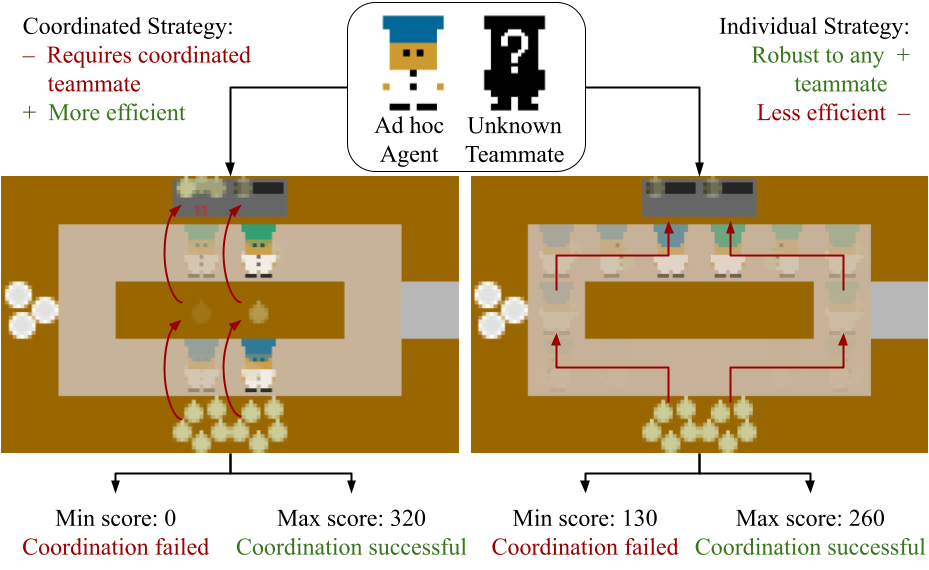
Two potential strategies in the simplified Overcooked environment used in this work.
To better understand the intricacies of zero-shot coordination, we analyze a scenario in the collaborative game “Overcooked”, in which players cook and serve onion soups. The above figure depicts two possible strategies: in the individual strategy, the blue chef and green chef each pick up onions and place them in their respective pots. The coordinated strategy has the blue chef passing onions to the green chef using the counter. While the latter strategy is faster, it will fail if coordination is not achieved. However, the former strategy can succeed even if only a single agent is productive. Ideally, when playing with a new teammate, an agent should be able to quickly identify which strategy to pursue based on their teammates play. We note that this an illustrative example: Overcooked requires many strategic decisions that depend on each layout and that continue to evolve throughout play. We also highlight that the strategies can only be reasonably described and understood at a task level—the low level description (e.g. left, left, up, up, right, right, up, interact,…) is not at a level of abstraction that a human could understand. Therefore, a key hypothesis that this work investigates is to understand if providing a hierarchical structure to an autonomous agent will enable it to align with their human teammates at the behavioral and cognitive level.
Importantly, a hierarchical approach provides the additional advantage of being able to tune an agent’s behavior after training is complete. In previous approaches, if a strategy does not emerge in training, it will never be used by the agent. However, having a high level agent in the system enables one to impart a bias on certain sub-tasks to produce strategies unseen during training. For example, if all teammates in the training population only use the individual strategies, then no RL agent would learn to use the coordinated strategy as it would never produce a better reward. However, with a hierarchical agent one can manually bias the “place onion on the counter” sub-task after training to promote the use of the coordinated strategy.
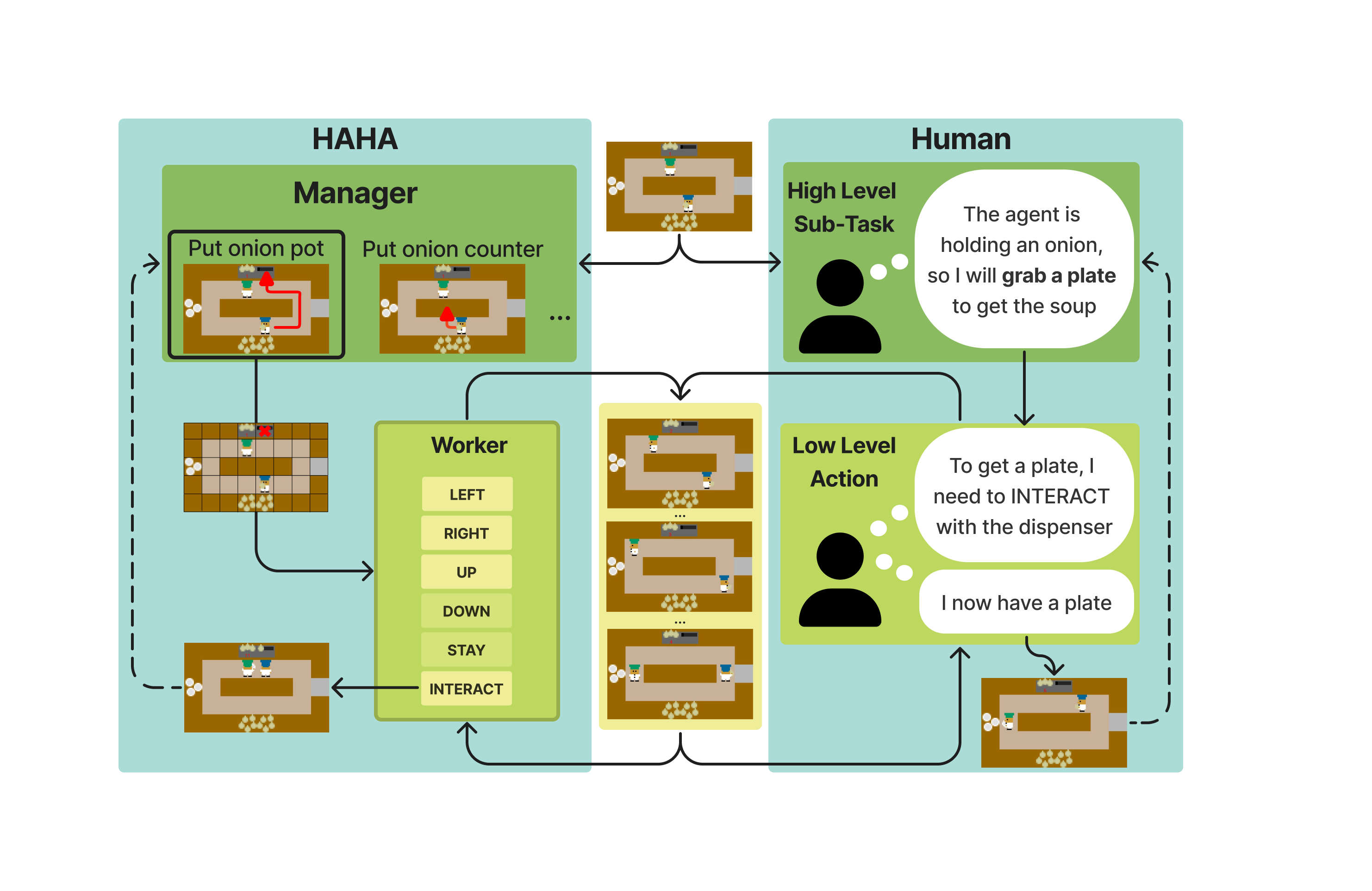
Architecture of the Hierarchical Ad Hoc Agents (HAHA). Similar to a human, the manager first selects which high-level task to accomplish next. The low-level worker then takes over to carry out the task.
To our knowledge, we are the first paper to propose, motivate, and demonstrate the benefit of using HRL for agents that interact with humans. Specifically, we propose the following novel contributions:
- We develop Hierarchical Ad Hoc Agents (HAHA) capable of zero-shot coordination with humans.
- We demonstrate that HAHA outperforms all baselines when paired with unseen autonomous agents.
- We demonstrate that HAHA outperforms and is preferred over baselines when paired with humans.
- We investigate leveraging the hierarchical structure to promote specific cooperative strategies post training. Our proposed hierarchical approach produces agents that can cooperate effectively with the rich diversity of human behavior, which can produce safe and efficient human-AI teams.
Code and full paper will be released soon.
References
[1] John Annett. 2003. Hierarchical task analysis. Handbook of cognitive task design 2 (2003), 17–35.
[2] Samuel Barrett, Avi Rosenfeld, Sarit Kraus, and Peter Stone. 2016. Making Friends on the Fly: Cooperating with New Teammates. Artificial Intelligence (October 2016). https://doi.org/10.1016/j.artint.2016.10.005
[3] Micah Carroll, Rohin Shah, Mark K Ho, Tom Griffiths, Sanjit Seshia, Pieter Abbeel, and Anca Dragan. 2019. On the Utility of Learning about Humans for Human-AI Coordination. In Advances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. Fox, and R. Garnett (Eds.), Vol. 32. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2019/file/f5b1b89d98b7286673128a5fb112cb9a-Paper.pdf
[4] Hengyuan Hu, Adam Lerer, Alex Peysakhovich, and Jakob Foerster. 2020. “Other-Play” for Zero-Shot Coordination. In Proceedings of the 37th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 119), Hal Daumé III and Aarti Singh (Eds.). PMLR, 4399–4410. https://proceedings.mlr.press/v119/hu20a.html
[5] Keane Lucas and Ross E. Allen. 2022. Any-Play: An Intrinsic Augmentation for Zero-Shot Coordination. In Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems (Virtual Event, New Zealand) (AAMAS ’22). International Foundation for Autonomous Agents and Multiagent Systems, Richland, SC, 853–861.
[6] Olivier Mangin, Alessandro Roncone, and Brian Scassellati. 2022. How to be Helpful? Supportive Behaviors and Personalization for Human-Robot Collaboration. Frontiers in Robotics and AI 8 (2022), 426.
[7] Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. 2021. Stable-Baselines3: Reliable Reinforcement Learning Implementations. Journal of Machine Learning Research 22, 268 (2021), 1–8. http://jmlr.org/papers/v22/20-1364.html
[8] Alessandro Roncone, Olivier Mangin, and Brian Scassellati. 2017. Transparent role assignment and task allocation in human robot collaboration. In 2017 IEEE International Conference on Robotics and Automation (ICRA). 1014–1021. https://doi.org/10.1109/ICRA.2017.7989122
[9] Neville A Stanton. 2006. Hierarchical task analysis: Developments, applications, and extensions. Applied ergonomics 37, 1 (2006), 55–79.
[10] DJ Strouse, Kevin McKee, Matt Botvinick, Edward Hughes, and Richard Everett. 2021. Collaborating with Humans without Human Data. In Advances in Neural Information Processing Systems, M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan (Eds.), Vol. 34. Curran Associates, Inc., 14502–14515. https://proceedings.neurips.cc/paper/2021/file/797134c3e42371bb4979a462eb2f042a-Paper.pdf
[11] Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. 2017. FeUdal Networks for Hierarchical Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning - Volume 70 (Sydney, NSW, Australia) (ICML’17). JMLR.org, 3540–3549.
[12] Gwydion Williams. 2022. Hierarchical Influences on Human Decision-Making. Ph.D. Dissertation. UCL (University College London).
[13] Yue Maggie Zhou. 2013. Designing for complexity: Using divisions and hierarchy to manage complex tasks. Organization Science 24, 2 (2013), 339–355.
Future Work
We are continuing to look into how to explicitly parametrize new teammates, as well as how to tune agents based on human feedback.
Please email Stéphane at stephane.aroca-ouellette@colorado.edu if anything on this page piques your interest (include [Q] in the subject line) or if you’re keen on collaborating (include [C] in the subject line).