Our goal is to catalyze tangible and substantial improvements in robot capabilities, especially in human–robot scenarios, with research at the confluence of learning, modeling, and robotics. We accomplish this from two perspectives:
- In the first, we leverage recent advances in learning and modeling to develop sophisticated, accessible, and generalizable robot technologies. Our focus here is primarily directed toward robots that operate in human environments. The ability of robots to interact or even cooperate with humans are considerations that are often neglected in the learning and modeling communities.
- Complementarily, we draw upon our expertise in robotics and human–robot interaction to inform foundational research in artificial intelligence—particularly in natural language processing and reinforcement learning. Our experience with real-world robotic systems allows us to underpin our research with strong empirical motivations, an approach that is conspicuously scant in much of the existing literature.
Contents
- 1. Projects
- 1.1. Multimodal Motion Planning
- 1.2. Enabling Long-term Robot Autonomy through Adaptable Fault Resilience
- 1.3. Planning with Dynamics Constraints
- 1.4. Non-Prehensile Manipulation
- 1.5. Natural Language Grounding
- 1.6. Multi-Agent Reinforcement Learning
- 1.7. Learning Discourse Policies for Dialog Management
- 2. Publications
1. Projects
1.1. Multimodal Motion Planning
Students: Anuj Pasricha

Leverage prehensile and non-prehensile skills for object manipulation.
The utility of autonomous robots in the real-world is primarily dictated by their ability to act in and reconfigure the operational environment. This requires robots to operate in coordination with humans and other robots, each with their own set of core skills (eg: throwing, pushing, catching, grasping, poking), to accomplish a task. Consequently, operating at the intersection of these skills and taking maximal advantage of each is a key landmark in enabling real-world use of robots. For instance, a manipulator may need to throw a packaged box into a bin located outside its reachable workspace, at which point it can be picked up by another arm and placed in a delivery truck. This multimodal nature of manipulation is grounded in robot capability, object characteristics, and environment configuration, and it demonstrates the need for a diverse portfolio of motion primitives that can be combined to exhibit dexterous manipulation behavior. In our research, we address the challenge of multimodal motion planning by employing sampling-based techniques. These techniques tap into dynamic models and control methods tailored for each skill, enabling the execution of complex manipulation tasks. We also incorporate recent innovations from artificial intelligence, specifically diffusion models, to make our approach more adaptable and applicable in diverse real-world scenarios.
1.2. Enabling Long-term Robot Autonomy through Adaptable Fault Resilience
Students: Gilberto Briscoe-Martinez
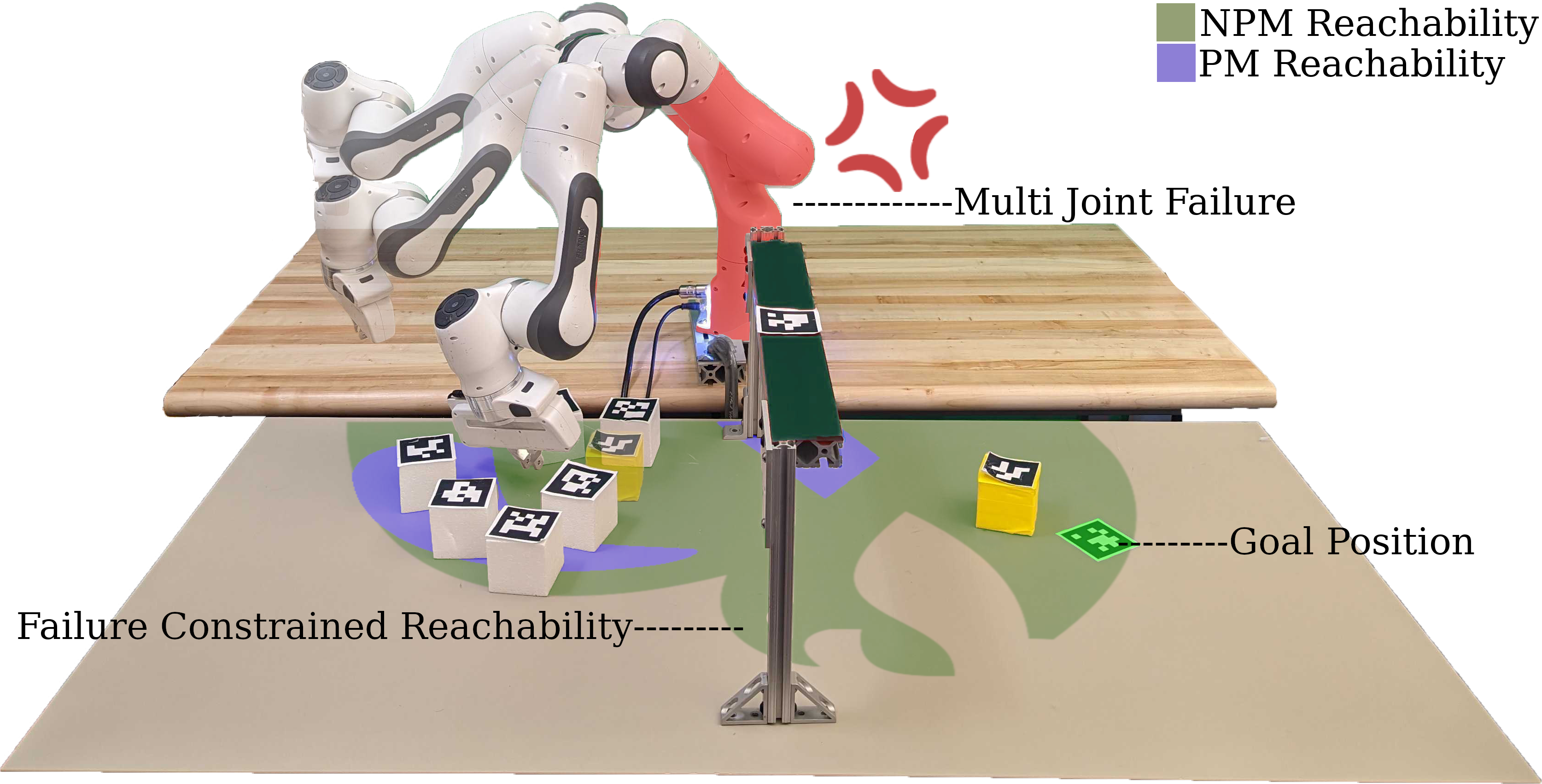
A Franka Emika Panda Arm completing manipulation tasks while experiencing locked, multi-joint failure.
This research project focuses on enhancing the resilience of robots in the face of system failures. The primary aim is to develop strategies that bolster their autonomy even in the aftermath of faults. To date, we have devised a system that evaluates the reachability of the robot post-failure, utilizes simulations to map available non-prehensile manipulation actions. Through searching and applying these actions, the framework enables effective planning and execution of manipulation tasks following a failure. Looking forward, the research will delve into understanding the impact of a robot’s system failure on its task completion probability. Additionally, future efforts will explore effective means of communicating the post-failure capabilities of the robot to human operators, fostering a more seamless collaboration between man and machine.
1.3. Planning with Dynamics Constraints
Students: Anuj Pasricha, Ava Abderezaei, Srikrishna Bangalore Raghu
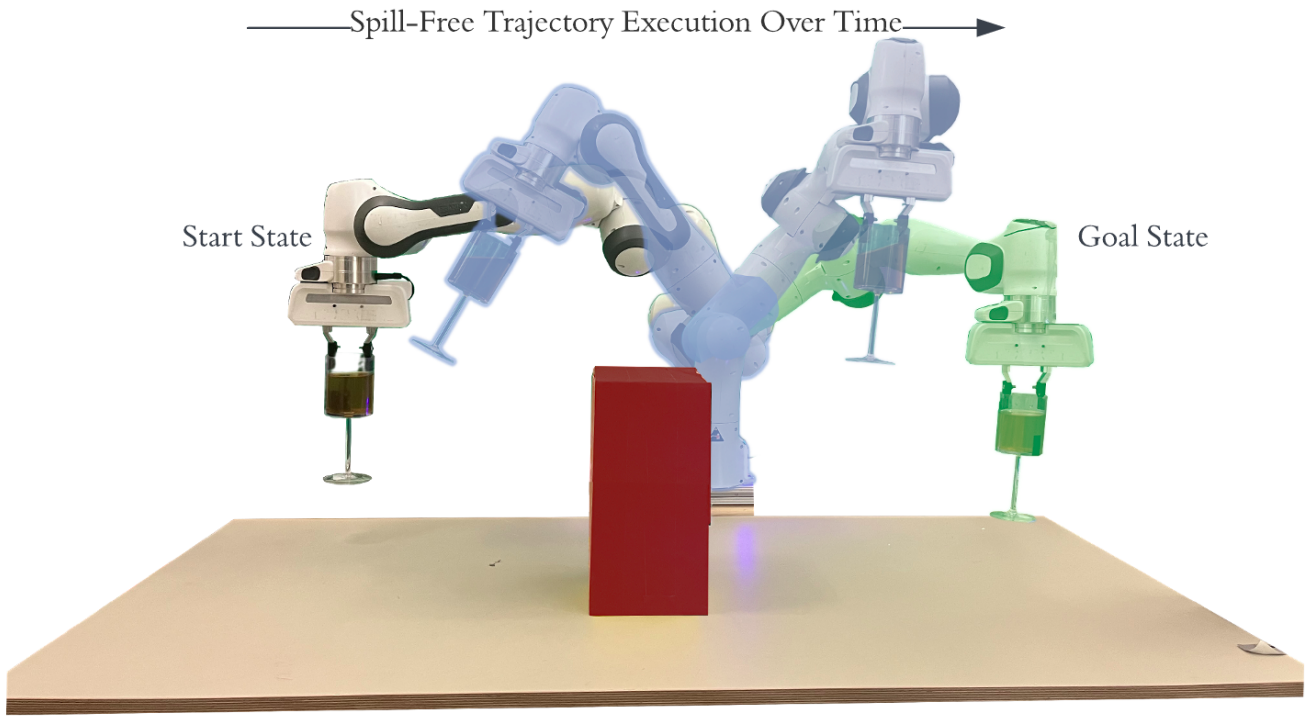
Transporting open-top containers while avoiding spillage.
Robotic manipulation in complex operational environments necessitates the integration of constraints at various levels of abstraction (i.e., kinematics, statics, quasi-statics, and dynamics) in order to effectively govern the interaction between the robot and its surrounding environment. These considerations show up in tasks involving liquid transport, deformable object manipulation, and nonprehensile manipulation, among many others. For instance, robotic fluid manipulation is challenging due to the intricate, nonlinear equations inherent to fluid dynamics. Solving these equations often demands significant computational time, making real-time precise control even more difficult, especially when aiming to avoid spills. Specifically, we work on incorporating analytical and learned dynamics constraints into a variety of sampling-based kinodynamic motion planners.
1.4. Non-Prehensile Manipulation
Students: Anuj Pasricha, Yi-Shiuan Tung
Publications:
- A. Pasricha, Y. Tung, B. Hayes, and A. Roncone, “PokeRRT: Poking as a skill and failure recovery tactic for planar non-prehensile manipulation” in Robotics and Automation Letters and 2022 IEEE International Conference on Robotics and Automation (ICRA), 2022. [PDF] [BIB]
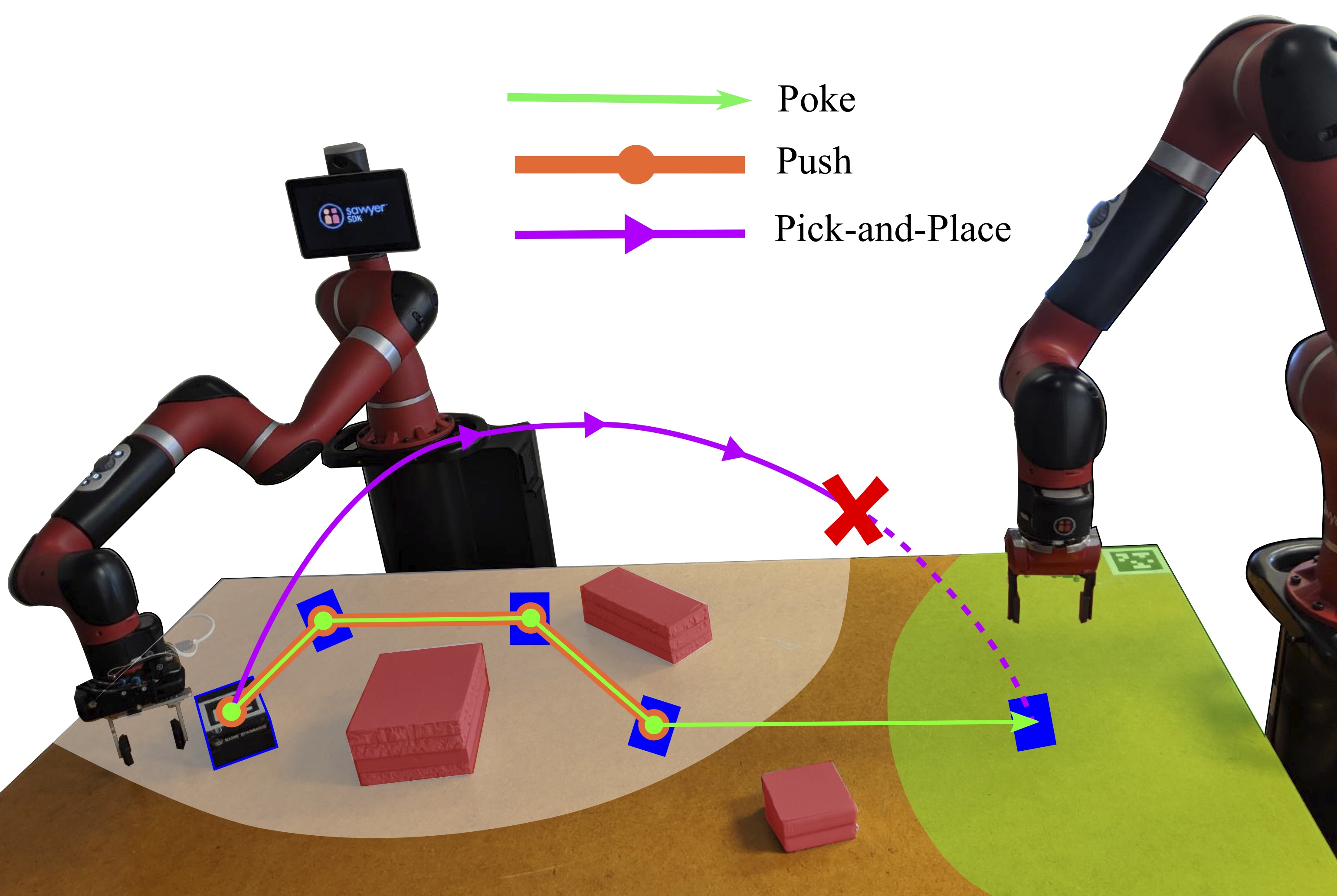
Expanding operational space by leveraging non-prehensile manipulation.
Non-prehensile manipulation (i.e., manipulation that does not involve grasping) can significantly expand the operational space of a robot. We posit that robots need to leverage non-prehensile manipulation as part of their skill set if they are to achieve human-level dexterity. Our past work introduced a novel planner that uses poking as a skill and failure recovery tactic synergistically with grasping. Moving forward, we are building hybrid models for manipulation in which physics-based and learning-based approaches complement each other, toward generating a repository of skills that robots can then use to engage in more complex, affordance-informed task planning and manipulation.
1.5. Natural Language Grounding
Students: Stéphane Aroca-Ouellette
Publications:
- S. Aroca-Ouellette, C. Paik, A. Roncone, and K. Kann, “PROST: Physical Reasoning of Objects through Space and Time”, 2021. In Findings of the Association for Computational Linguistics: ACL-IJCNLP2021, [PDF] [BIB]
- C. Paik, S. Aroca-Ouellette, A. Roncone, and K. Kann, “The World of an Octopus: How Reporting Bias Influences a Language Model’s Perception of Color”, 2021, In Empirical Methods in Natural Language Processing: EMNLP2021, [PDF] [BIB]
Natural language serves as the fundamental medium through which humans collaborate, providing a versatile framework for articulating tasks, exchanging information, and conveying intentions. While modern language models have shown impressive results, it is essential to recognize a key distinction between how humans and language models acquire language. Humans learn language by experiencing it in the real world, in contrast language models predominantly rely on text data alone for their learning. To this end, we posit that the pursuit of text-only training is at a minimum inefficient, and possibly insufficient to achieve a human-like understanding of language. Our initial work PROST highlighted one area where text-only models fall short—understanding questions related to physical reasoning—and demonstrated that scale alone would be unlikely to solve this shortcoming. Upon delving deeper into this issue, our next paper identified a potential underlying factor: reporting bias. Due to human’s experience in the world, self-evident information is often omitted from text. For example, if someone says “I knocked my glass off the table”, most do not elaborate further with information such as “the effects of gravity pulled the glass to the ground, breaking on impact, and the making the ground wet with its content.” Rather, we rely on our own experiences of similar events to fill in these important details. Having identified these limitations, we are currently investigating methods to ground language in embodiment inorder to improve the understanding of language models. Ultimately, we hope that these improved language models will help improve natural language task specification systems.
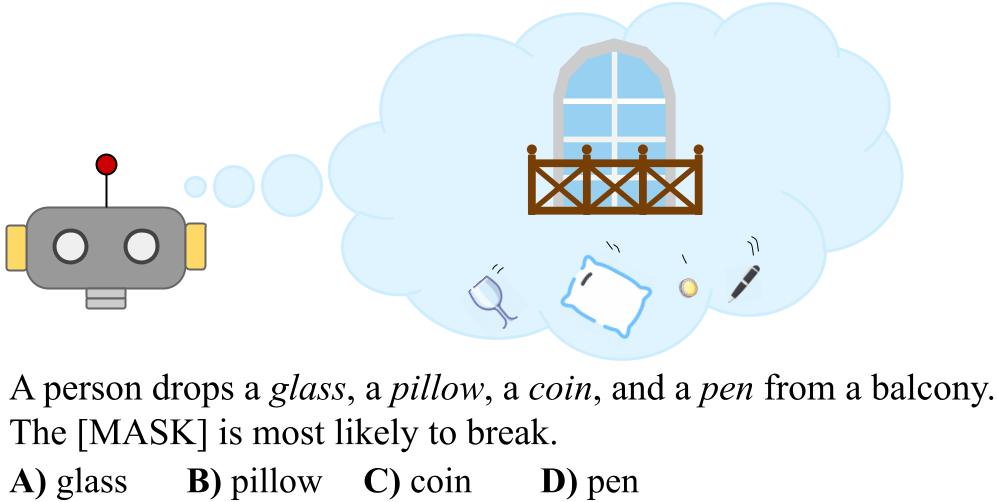
An example question from PROST.
1.6. Multi-Agent Reinforcement Learning
Students: Joewie J. Koh, Chi-Hui Lin
Publications:
- C. Lin, J. J. Koh, A. Roncone, L. Chen, “ROMA-iQSS: An Objective Alignment Approach via State-Based Value Learning and ROund-Robin Multi-Agent Scheduling,” in 2024 American Control Conference (ACC), 2024. [PDF] [BIB]
- J. J. Koh, G. Ding, C. Heckman, L. Chen, A. Roncone, “Cooperative control of mobile robots with Stackelberg learning,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020. [PDF] [BIB]
- G. Ding, J. J. Koh, K. Merckaert, B. Vanderborght, M. M. Nicotra, C. Heckman, A. Roncone, L. Chen, “Distributed reinforcement learning for cooperative multi-robot object manipulation,” in 19th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2020. [PDF] [BIB]
Reinforcement learning (RL), which allows an agent to learn from interactions with its environment, presents an increasingly promising alternative to traditional model-based control. However, much of the work applying RL to robotics has been in the single-agent paradigm—despite the pervasiveness of multi-agent robotic systems in the real world. We are most interested in developing algorithms for controlling heterogeneous teams that cooperate to accomplish common goals, with the aim of enabling multi-robot systems to be imbued with capabilities that are more than the sum of their parts. Moreover, we envision multi-agent systems serving as the setting for the next wave of progress in RL research, and are further driven by the belief that multi-agent RL can provide a theoretical basis for understanding the application of RL in human–robot contexts.
Learning to cooperate with asymmetric perceptual capabilities.
1.7. Learning Discourse Policies for Dialog Management
Students: Joewie J. Koh, Kayleigh Bishop
The NSF National AI Institute for Student-AI Teaming (iSAT) is a multi-site interdisciplinary institute with the vision of developing artificial intelligence as a social, collaborative partner that helps both students and teachers make learning more effective, engaging, and equitable. As a part of this institute, we conduct foundational research on dialog management for AI-based conversation participation and facilitation. Specifically, we are studying how reinforcement learning might be applied to autonomously generate and fine-tune discourse policies.

iSAT's vision for student-AI teaming and classroom orchestration.